

Have you heard about Azure Data Explorer, formerly known as project Kusto? The new PaaS from Microsoft that enables fast and highly scalable data exploration? The service that empowers Azure Monitor and Time Series Insights?
Fear not! As of 7 February 2019 it was announced to be General Available, meaning that it’s the new kid on the block. I will therefore dive into the nitty-gritty details in a series of blog posts that hopefully gives you enough information to get started yourself.
What do you need?
Working with Azure Data Explorer requires as everything else – source control and automation of deployments. I recommend that you start using the latest version of Az PowerShell with the Az.Kusto module to manage the clusters and databases.
For now you will use the Azure Data Explorer Query Explorer, but if you are planning on automating deployments using Azure DevOps take a look at the plugin Azure Data Explorer – Admin Commands. The plugin enables you to run admin commands like creating tables, enforcing table policies and so on from the release pipeline.
Creating your first database and table
Let’s assume that you have have provisioned the cluster and is ready to create the database. Open PowerShell and log in to your Azure account. Set the context to where the Azure Data Explorer is provisioned.
Load the Az.Kusto module inside PowerShell ISE and run the below command. This will create a database named myadxdb with policies for hot cache and soft delete set to one day. These policies should be based on the requirements you have for the project.
Wait for the command to complete. When it’s finished your database should be visible at the azure resource page under the databases selection.
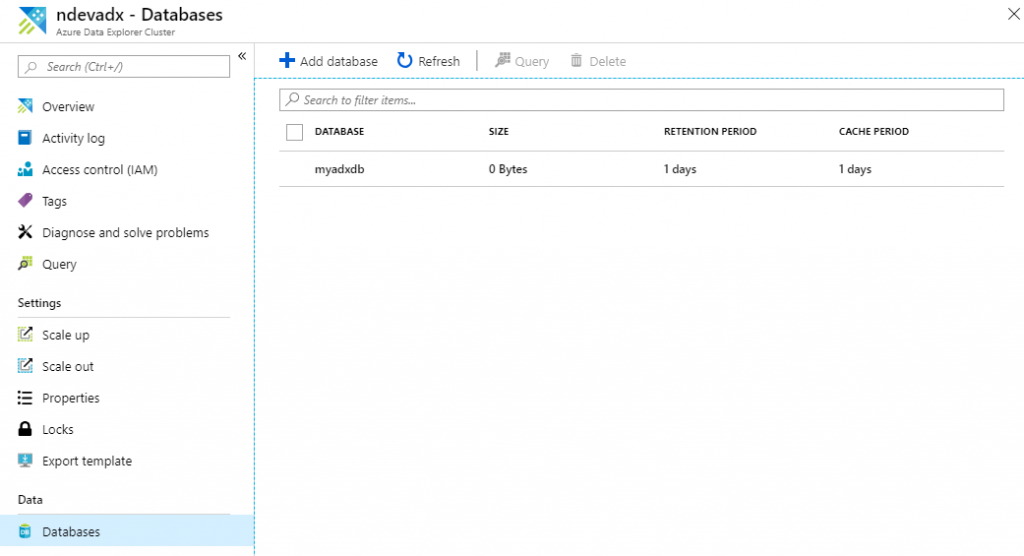
Now that the database is created, let’s create the first table using the query explorer. This can be accessed by clicking at the query option at the azure resource page.
For demonstration purpose you will create a table named WeatherLog. In the upcoming series you are going to populate it with weather data, but for now copy-paste the below statement to the query editor in your browser and execute it.
Once the command is done executing it will return the result as a JSON with the schema that was created, and if you take a closer look you will notice that the timestamp column is missing. I guess that is quite crucial when logging weather data?
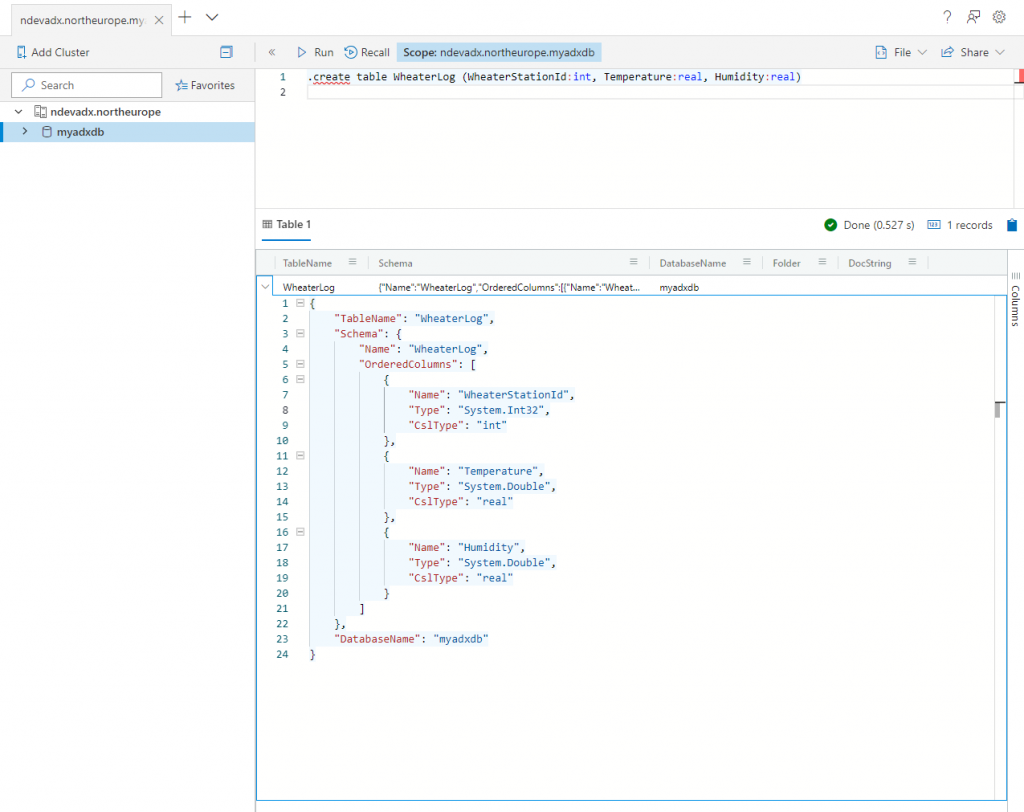
Add a timestamp column to the create statement and run it again.
Did you notice that the same JSON was returned? Use the .create-merge table instead of .create table command as it will update the table definition, but take note that the .create-merge command also behaves as a create when the table does not exists.
Congratulations on creating your first database and table!
Note! As you probably have been observing, the create table commands starts with a dot. According to the documentation this is done for security purposes, and at the language level it determines if the request is a control command or a query.
What about maintainability?
Creating tables, policies and so on for the database is of course easy to do when using the query explorer, but not maintainable at a long term basis. This brings me to the next point I want to highlight. It’s important that you version the code and structure the source control repository so that it makes sense from a deployment perspective and is manageable on a day-to-day basis. In most simplest form you can structure the Azure Data Explorer repository something like the below image.
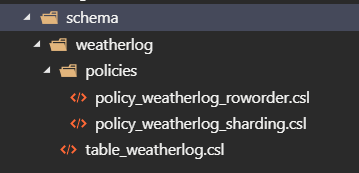
The idea here is the following
- The schema directory contains a sub-directory for each table in a given database. Each table directory has a belonging script for the table definition.
- Below each table directory we add the policies to a separate sub-directory so that it’s easy to see the policies that are enforced.
- The prefix on each file is mainly added for deployment purposes. The idea is that Azure DevOps can be configured to deploy code in the correct order.
There is of course more to consider when versioning; especially when to use .create compared to .create-merge, how to handle deployment and deployment errors, how should you deploy multiple tables at the same time, and much more.
Stay tuned for the upcoming series where I will dive deeper into the world of Azure Data Explorer. Until then I would love to hear from you! Have you started using Azure Data Explorer, and what are your thoughts and impressions so far?
Warning! Remember to remove or pause you Azure Data Explorer cluster when not using it.
